Vanishing Gradient Problem!
What? Why? And how to fix it?
In simple words, the Vanishing Gradient means a Gradient or derivative value which has almost vanished or which is negligible. A vanishing Gradient is a problem that occurs during backpropagation in the neural networks when we are trying to train our model. If this problem occurs in the model then after a point there will not be any training possible in the model. A vanishing gradient occurs in complex neural networks where the number of hidden layers is more or when we are using sigmoid or tanh activation functions to train our model.
What is the Vanishing Gradient?
A vanishing gradient occurs during backpropagation where we move back in every layer and change the value of weights to attain a better result.

Once we have the output from our last Node we check the loss using the (predicted value)— (actual value). Now in order to achieve a better result, we move backward to change the value of weights.
Weight(new)= Weight(old)- learning rate(derivative of weight).
Why Vanishing Gradient Occurs?

Consider the above image where the value of B(y^) depends on the weights 01 and 02. In the case of backpropagation, we are moving from B to 01 so that we can change the value of 01 and 02. But in the case of the vanishing gradient problem, the derivative of 01 becomes very less like 0.001.
In order to attain the weight, 01(new) = 01(old)- learning rate* derivative.Assuming the learning rate to be 0.1 we have
01(new) = 01(old)- (0.1*0.001)
01(new)=01(old)-0.0001.
Here we can see any value when subtracted by 0.0001 will bring negligible change to the value, hence there won't be any change in the value of 01(new) and hence the model will not be able to train itself further.
How to identify a Vanishing Gradient?
- No change in loss function: After multiple epochs, if the value of the loss function is not changing then it shows the model is encountering a vanishing gradient.
- Weight graph: Plot a graph of the weight having epoch and value as the x,y. If the graph is consistent then it means the model has encountered a vanishing gradient.
How to handle Vanishing Gradient?
- This problem occurs when the model is very complex. By decreasing the complexity of the model or bringing down the number of hidden layers we can decrease the probability of Vanishing Gradient.
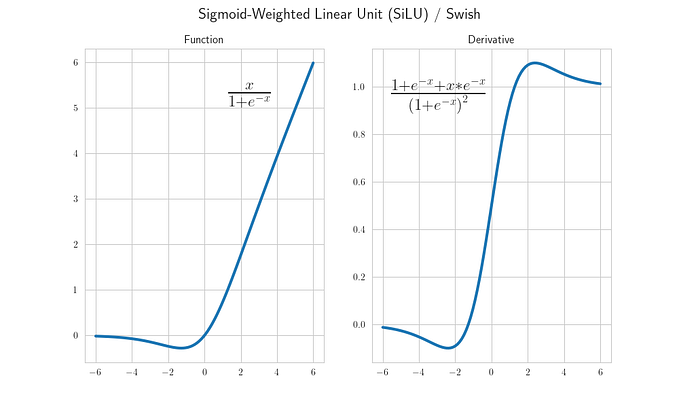
- Changing the activation function to Relu: Sigmoid and Tanh are considered the main reason for the Vanishing Gradient. Shifting to Relu or leaky Relu can bring down the chances of the problem.
- Proper Weight Initialization: There are certain weight initialization techniques like Glorat and Xavier which can help in proper weight initialization which can further bring down the chances of the Vanishing gradient.
The article gives a deep understanding of the Vanishing Gradient. I hope you find this article useful.